As privacy trends continue to diminish the accuracy of direct attribution data, brands are increasingly turning to Media Mix Modeling, an umbrella term for a set of econometric models that correlate marketing spend and other activities to business outcomes, to understand the impact of their paid media investment. A recent survey revealed that over 80% of top consumer brands are investing in or considering investment in an MMM solution.
For brands at scale, MMM can be a powerful tool for understanding and optimizing paid media efficiency. Nevertheless, many brands we meet with struggle to extract actionable insights from their MMM. This is rarely due to a lack of sophistication or “correctness” in the models themselves. Rather, most brands are failing due to a lack of effective process for evaluating and validating their MMM outputs against direct attribution data and dedicated testing. Often, we see brands letting MMM builds exist in a silo with their data science team or a third party vendor and accepting its output at face value as a “ground truth” for decision making.
To be effective, an MMM program needs to go beyond just data collection and machine learning. At Headlight, we incorporate a continuous validation process where we seek to take model outputs, testing outcomes, and direct attribution data to build a holistic view of measurement. This approach grants us insights that aren’t immediately apparent from model outputs directly, which we can in turn use to improve model performance and drive decision making. We’ve put together a breakdown and case study below on how we accomplish this.
How We Build & Use Media Mix Models
The core output of Headlight’s MMM toolset is a breakdown of how a given backend metric — like conversions or revenue — is influenced by external factors such as channel or overall marketing spend, and the potential impact modifying those factors may have moving forward. The model provides an alternative, incrementality-based breakdown of the contribution each channel has to the bottom-line. This decomposition can be cleanly compared against the attributed channel views over the same time period to derive halo coefficients, which convert a traditionally attributed CPA to one based on incremental impact. Optimizing your budget for equilibrium across these incrementality-adjusted CPAs ensures you’re maximizing the value of each incremental dollar across the full media mix.
From a high level perspective, the core forecast from our modeling predicts the percentage contribution of each input factor. While channel spend is a key contributor, other non-spend sources of KPI impact can also influence the outcome. Beyond spend, non-paid marketing efforts, sales and other external factors, we may also want to take into consideration doing segmentation of model KPIs on things like geo tiers or platform. The end result is a model that predicts each factor’s contribution to the KPI segment in question:
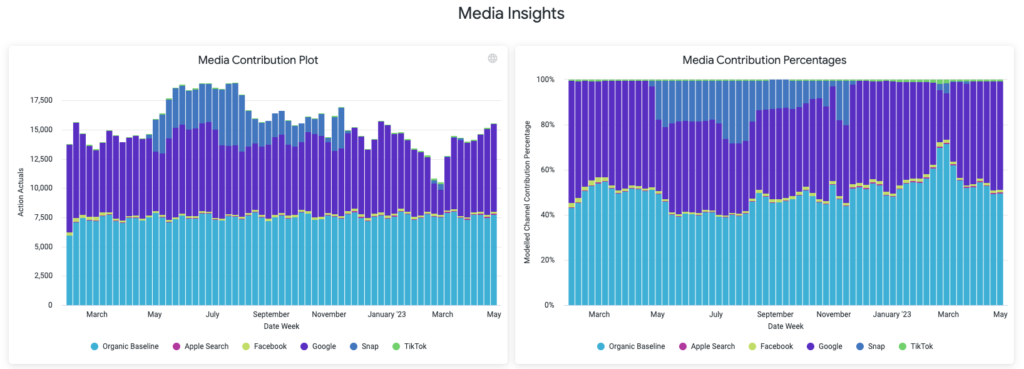
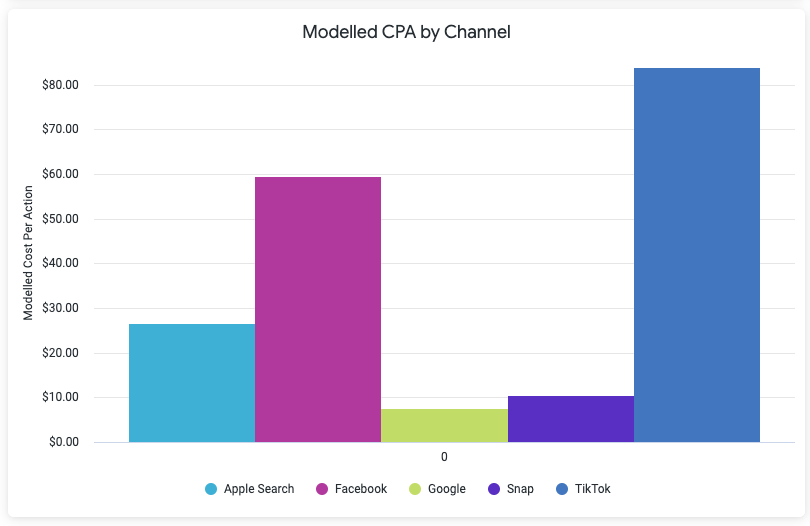
The predictions highlight contributions that can be used to calculate the CPA/ROAS for each channel concerning the key performance indicator. By comparing these modeled CPAs with direct sources like SKAD reporting or multi-touch backend attribution, discrepancies in attribution can be spotted. Bypassing traditional problems like channel overclaim, SKAD underreporting, and cross-platform tracking, this method offers a more transparent view of historical media contributions. Such historical data can then be factored in when analyzing attributed metrics, allowing for the application of modeled coefficients.
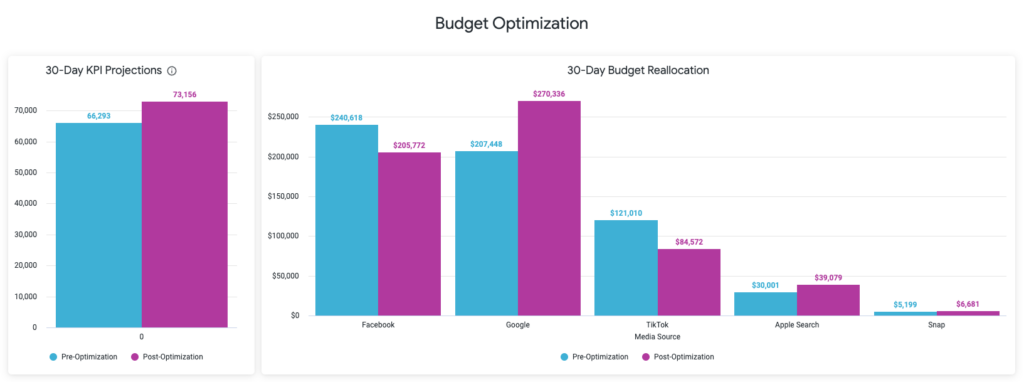
Our models will also produce budget optimization guidance, based on historical spend impact. This output is a great guidepost for budget optimization opportunities, but this is obviously where validation of historical incrementality becomes extremely important:
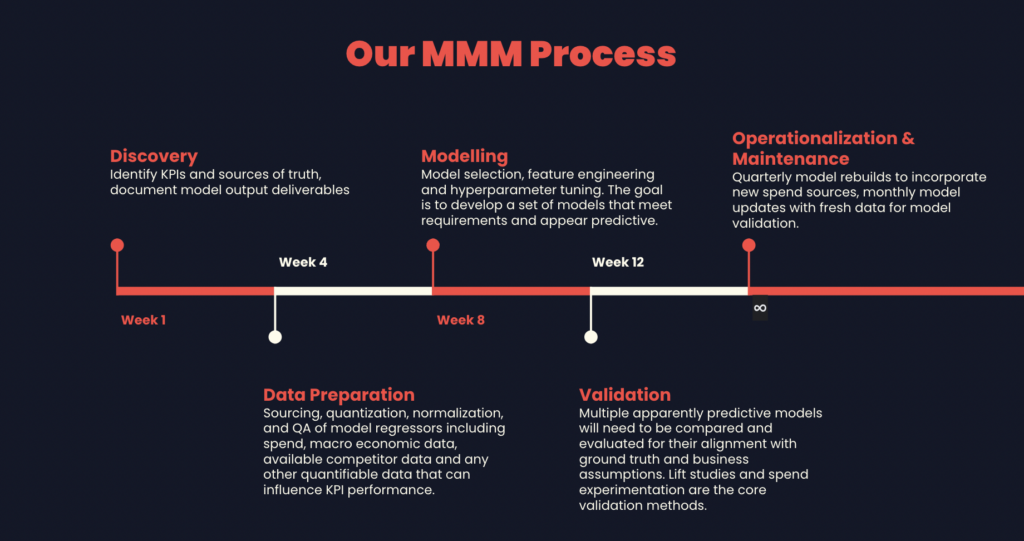
Establishing a monthly modeling cadence for these outputs typically requires three to six months of upfront investment in data engineering and machine learning work. While it’s true that all of the intricacies of attribution can readily be sidestepped by most MMM approaches, sources of truth need to be identified, validated and tidied for use in modeling work. Spend, both digital and otherwise is the most important (and likely the easiest to acquire) but there are others as well, such as:
- Prevailing market conditions (macro-economic trends, regulatory changes, competitor sales/campaigns) – If blended/organic performance obviously shifted as a result of factors external to spend during the sampling period, it’s important to quantize and include that information in modeling.
- Product or funnel changes – Any major funnel shift that may have impacted conversion rates will impact the perceived response of metrics to spend, so it’s important to isolate as many of these factors as possible.
- Pricing/Sales – Similar to funnel updates, this will obviously impact conversion rates. It can also be relevant if specifically modeling for revenue metrics.
Once the initial work of identifying the relevant data and sourcing it is done, preparing and running models can begin. The workflow here involves an iterative feedback loop where models are tested and outputs reviewed in conjunction with marketers. Through this process we’re looking for a model that is both predictive in out-of-sample data, but also aligns with ground truths that we’ve established through external testing. There is a need for constant feedback between the data scientists performing the analytics work and the marketers and product teams familiar with the campaigns, product adjustments and any other forces that may have impacted performance.
The Importance of Validation
The culmination of data science and engineering work is a model that can reliably provide insights derived from past performance when tested against out of sample data. While this is great, it doesn’t necessarily provide actionable insights in and of itself. It’s very possible to have a predictive model that isn’t reflective of reality.
For example, Robyn, one of the tools we and many other use when generating MMM outputs, can very easily generate models with wildly different attribution claims that perform similarly when the only metric is out of sample prediction error. This example, using Robyn’s own sample demo data shows how the same inputs result in a large variance between perceived media contribution and ROI, in this example showing a wide variance between ROI for TV and OOH spend:
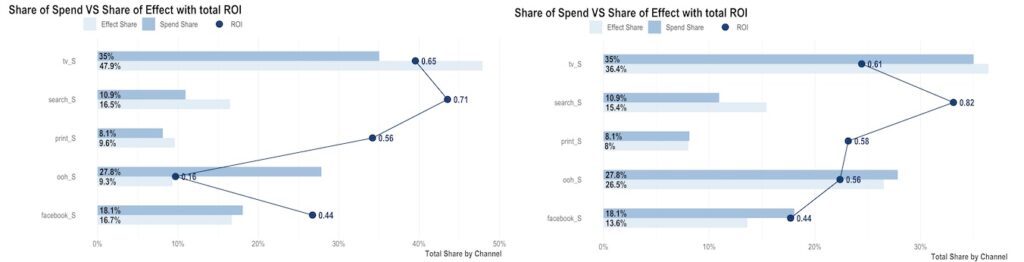
Additionally, the model can’t anticipate the changes that will impact future performance. Major shifts in conversion rate from some of the aforementioned external factors (pricing changes, funnel updates, market shifts) will mean that modelled predictions won’t hold for future spend.
These are the reasons why it’s so important to tie the data science and machine learning outputs with an ongoing testing and validation framework. The work of operationalizing and validating the model is ongoing. Each new channel represents a new potential set of regressors that must be fed in and re-evaluated. Each user acquisition funnel change could result in a shift in conversion rates that invalidates prior funnel performance assumptions. By maintaining a running re-modeling cadence, and routinely comparing the results of those models with real world performance, you can establish a long term set of ground truths to work against that make highlighting performance shifts and opportunities easier and easier. Beyond validation of predictions through controlled spend testing, it’s also important to factor in results from match market tests and conversion lift studies. The results of these can even be utilized directly during modelling as constraints on modelled performance assumptions.
An Example of Validation in Practice
Failure to properly bake business context into your model and then thoroughly validate the model’s outputs leaves an advertiser susceptible to blindspots that will guide your decision-making down the wrong path.
To illustrate with an example, we recently had an MMM run for a client that suggested Google AC was performing at a much more efficient CPA than what our direct attribution data told us, and recommended a substantial increase in budget. Rather than immediately actioning this, the team dug in further to analyze the historical context and uncover why the model might have predicted this. Our model was built on two years worth of client data, and our deep dive uncovered that, three months prior, a key onboarding change unique to the Android app caused Google AC to become less incremental over time. Other channels were unable to recover these lost conversions, indicating their true incremental nature.
As over 80% of the model’s sample data occurred prior to these changes, its net recommendation did not accurately reflect the current scalability of the channel. A small in-market test where we moved 15% of budget from Meta to UAC for ten days confirmed these findings as blended CPA increased 4%. This finding opened a dialogue with the client around the feasibility of reverting or modifying the product in effort to regain the lost incrementality.
At its core, a model is just a sophisticated math equation that has no internal sense of how ‘correct’ it is. The same model can produce a number of different outputs that all have the same predictive power, but tell very different stories. If taken at face value, you can get bamboozled! Blindly following an improperly validated MMM can lead your growth program into a rut with significant negative business consequences that can be difficult to climb out of.
A Holistic Approach
As deterministic measurement data becomes less and less reliable, it is critical to get ahead of the trend by working to future-proof your measurement strategy. At Headlight we believe that MMM can establish a new pillar in an advertiser’s measurement toolset. The key differentiator is working with a team who knows what to look out for from the earliest inception stages all the way through to real time validation and tuning. It can be tempting to silo the data science and marketing teams, or take an all or nothing approach with regards to accepting modelled predictions. As is often the case though, the optimal solution requires a lot more effort. If you’re looking to adopt media mix modelling as part of your performance marketing toolkit, it’s important to take into account the data engineering, data science and marketing resources you’ll need to bring to the problem and make sure you have a framework in place to allow coordination of testing and validation.
Get Growth Insights Delivered to Your Inbox


